Tenglong Ao 敖腾隆
Ph.D
Biography
Ph.D in computer science from Peking University. B.S. degree in electronic engineering from Tsinghua University.
Some work:
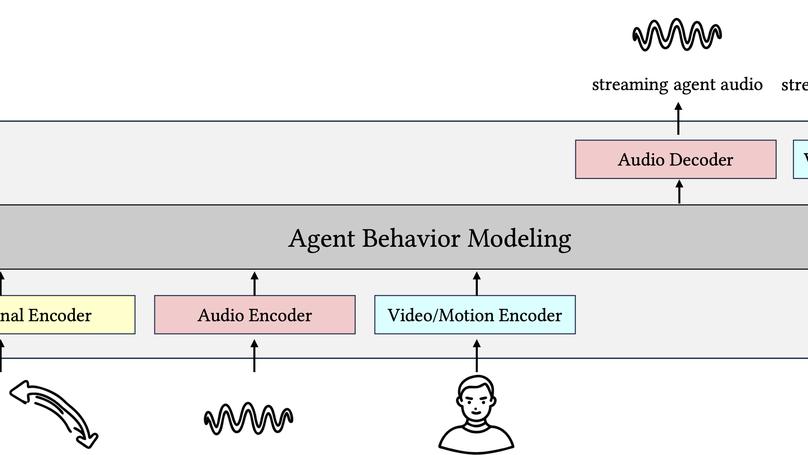
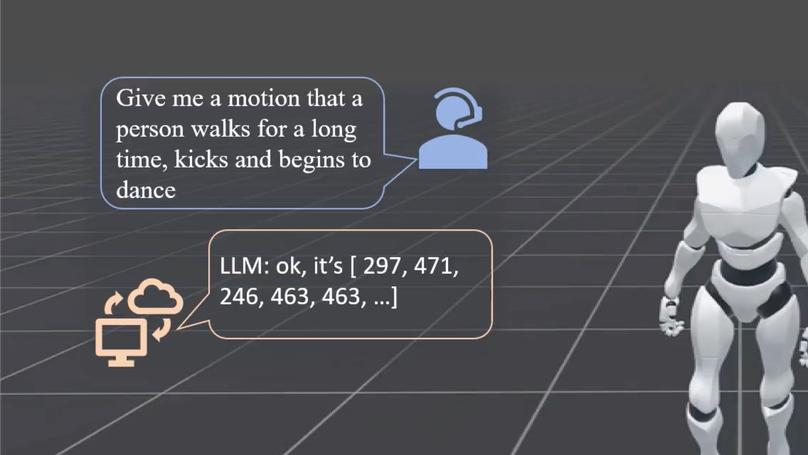
- Body of Her: a real-time, full-duplex, multimodal autoregressive model for voice and video.
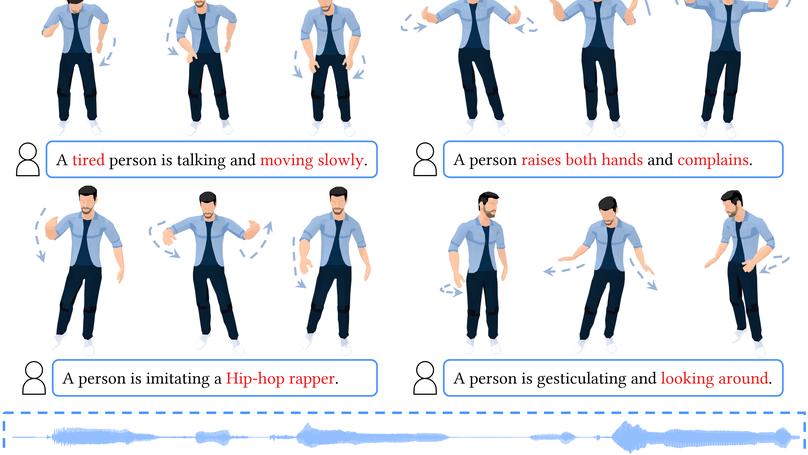
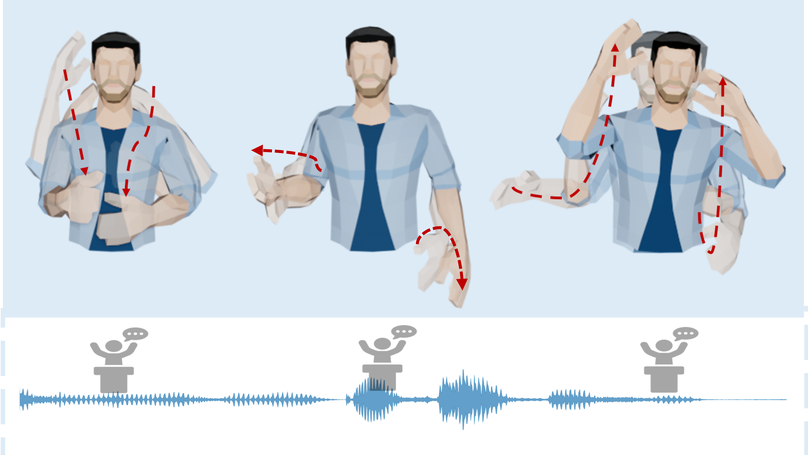
- Graphics Animation: Co-Speech Gesture Synthesis (SIGGRAPH (Asia)‘22 Best Paper & SIGGRAPH (NA)‘23 Best Paper Honorable Mention); Visual Storyteller (startup, storytelling animation maker).